Data-Mining der Suchbegriffe auf Namensindex.org
10.12.2023, Clemens Draschba
Bereich: Wissenswertes für die Familienforschung
Eine spannende Data-Science Analyse der Begriffe aus der Bestandssuche der letzten zweieinhalb Jahre.

Sowohl beruflich als auch privat bin ich immer auf der Suche nach neuen Technologien, die interessante Ergebnisse versprechen. Inspiriert durch die unterhaltsamen Vorträge des bekannten deutschen Data-Scientisten David Kriesel auf dem Communication Congress (CCC) über "Spiegel-Mining" (33C3) und "Bahn-Mining" (36C3), habe ich mich entschlossen, wieder einmal ein kleines Datenexperiment selbst durchzuführen. David Kriesel vermittelt in seinen Vorträgen nicht nur humorvoll und leicht verständlich, sondern auch verantwortungsbewusst die Mächtigkeit und Potentiale der Methoden aus der Data Science.
Auf Namensindex.org speichern wir seit März 2021 bei jeder Eingabe in der Bestandssuche den Suchbegriff zusammen mit einem Zeitstempel ab. Wohlgemerkt, dabei handelt es sich nicht um die Namenssuche in den standesamtlichen Registern, sondern um die Suche nach Aktenbeständen aus den polnischen Staatsarchiven, die bei uns im Projekt hinterlegt sind. Die Tabelle enthält nur die Spalten „search_term“ (Suchbegriff) und „search_date“ (Suchzeitpunkt), mithin also keinerlei personenbezogene Daten. Normalerweise nutzen wir diese Daten, um festzustellen wann und mit welchen „üblen Tricks“ unsere Webseite durch Hackerattacken angegriffen wird. Dies erkennt man recht schnell an den „ungewöhnlichen“ Suchbegriffen, die in kürzester Zeit automatisiert an unsere Suchfunktion gesendet werden.
Filtert man diese Daten aus dem Datenbestand heraus bleiben die „ehrlichen“ Suchanfragen von den Familienforschern übrig. Der Datensatz deckt mit insgesamt 61.321 Anfragen nach Filterung den Zeitraum vom 05. März 2021 bis einschließlich 30. November 2023 ab. Und mit diesem Datensatz wollen wir im Rahmen dieses Beitrages drei Dinge tun:
- Wir ermitteln welche Begriffe am häufigsten gesucht werden. Wir machen also eine Auswertung über das Feature der Spalte „search_term“.
- Wir analysieren die Daten auf der Basis des Zeitstempels „search_date“ und schneiden die Daten in verschiedene zeitliche Epochen, um Informationen über das Nutzungsverhalten der Suchenden zu erhalten.
- Wir erstellen eine dritte Art von Analyse, indem wir die Suchbegriffe und die Zeitstempel miteinander in eine Beziehung setzen und als gemeinsames Features auszuwerten, um damit eine "Suchlandkarte" der Beziehungen zwischen den Begriffen zu erstellen.
Der Werkzeugkasten, den wir für die Datenanalyse verwenden, besteht aus einem Jupyter Notebook, in dem mit der Sprache Python und dem integrierten Framework Pandas sehr einfach Auswertungen durchgeführt und gleichzeitig grafisch visualisiert werden können. Für die Auswertung haben wir alle Suchbegriffe in Kleinbuchstaben umgewandelt, da unsere Datenbank dies ebenfalls tut und die Daten so besser vergleichbar sind.
1. Auswertung der Suchbegriffe
Die häufigsten Top 50 der Suchbegriffe:
Die Ermittlung der 50 häufigsten Suchbegriffe und deren Anzahl lässt sich mit Pandas in einem einzigen knackig formulierten Statement durch
- Gruppierung aller Datensätze nach den Begriffen,
- zählen der Anzahl der Vorkomnisse
- und anschließender absteigender Sortierung nach der Anzahl
durchführen. Das formulieren wir im Jupyter Notebook durch verkette Aufrufe der Pandas Objektfunktionen in einem einzigen Kommando:
searchlog.groupby('search_text').size().to_frame('anzahl').sort_values( by='anzahl', ascending=False).head(50)Hier das Ergebnis als Tabelle aus dem Pandas Datenframe:
| Platz | Begriff | Anzahl | Platz | Begriff | Anzahl |
|---|---|---|---|---|---|
| 1 | königsberg | 312 | 26 | angerburg | 102 |
| 2 | allenstein | 296 | 27 | tilsit | 100 |
| 3 | gumbinnen | 272 | 28 | goldap | 99 |
| 4 | lötzen | 253 | 29 | schimonken | 98 |
| 5 | soldau | 241 | 30 | braunsberg | 97 |
| 6 | elbing | 240 | 31 | marienwerder | 94 |
| 7 | danzig | 220 | 32 | heilsberg | 89 |
| 8 | lyck | 197 | 33 | marienburg | 87 |
| 9 | ortelsburg | 192 | 34 | preußisch holland | 82 |
| 10 | osterode | 190 | 35 | thorn | 81 |
| 11 | sensburg | 172 | 36 | fischhausen | 81 |
| 12 | neidenburg | 165 | 37 | rhein | 80 |
| 13 | mohrungen | 155 | 38 | schönbruch | 76 |
| 14 | rastenburg | 153 | 39 | kraplau | 74 |
| 15 | bromberg | 147 | 40 | eckersberg | 74 |
| 16 | bartenstein | 143 | 41 | labiau | 74 |
| 17 | milken | 138 | 42 | hohenstein | 73 |
| 18 | insterburg | 135 | 43 | holland | 73 |
| 19 | widminnen | 134 | 44 | deutsch eylau | 72 |
| 20 | passenheim | 133 | 45 | rheinswein | 70 |
| 21 | warweiden | 130 | 46 | pillkallen | 67 |
| 22 | graudenz | 128 | 47 | jodlauken | 66 |
| 23 | friedrichshof | 125 | 48 | nikolaiken | 65 |
| 24 | rössel | 116 | 49 | engelstein | 65 |
| 25 | johannisburg | 108 | 50 | guttstadt | 65 |
Bei allen 50 Suchbegriffen handelt es sich um Stadt- oder Ortsnamen aus dem Forschungsgebiet des ehemaligen Ost- oder Westpreußens. Dies ist kaum verwunderlich, da die gezielte Suche nach Sekundärakten zu bestimmten Regionen und Ortschaften zu den häufigsten Fragestellungen von Familienforschern im Rahmen unserer Bestandssuche gehört.
2. Auswertungen nach der Zeitspalte
Bei der Auswertung der Zeitspalte gehen wir analog zur Auswertung der Suchbegriffe vor: Wir gruppieren die Datensätze nach Datum, Uhrzeit, Wochentag und Monat der Suchanfrage und zählen jeweils die Häufigkeiten.
2.1 Anzahl täglicher Suchanfragen
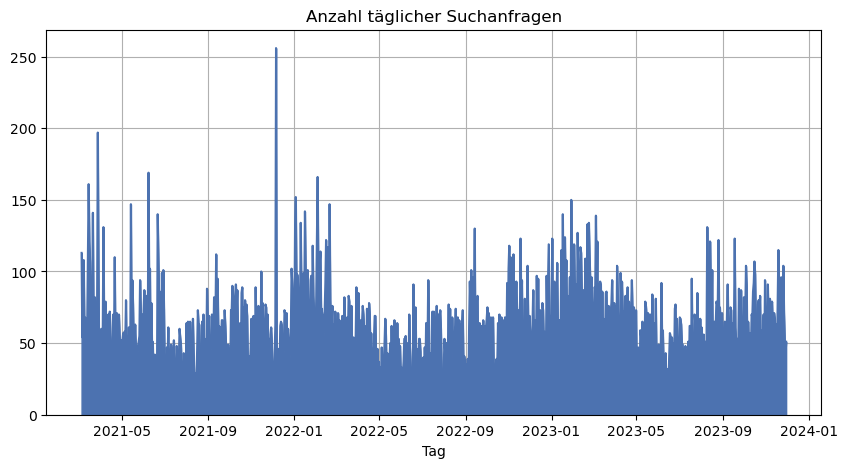
Die Gesamtzahl von 61.321 Suchanfragen verteilt sich auf 1001 Tage zwischen dem 05.03.2021 und dem 30.11.2023. Wir erhalten also im Durchschnitt etwa 61 Anfragen pro Tag, was ein durchaus überschaubares Volumen darstellt. Der auffällige Spitzenwert am 06.12.2022 von 256 Anfragen ist scheinbar auf einen Versuch zurückzuführen, unsere Suche mit Hilfe einer Software automatisiert nach bestimmten, immer wiederkehrenden Begriffen abzufragen. Dieser Anschein ergibt sich auch aus dem Umstand, dass alle Anfragen in einem extrem kurzen Zeitintervall abgegeben wurden. Da an diesem Tag jedoch nach sinnvollen Begriffen aus der Region Soldau gesucht wurde haben wir dies nicht als „Angriff“ auf unsere Suchfunktion gewertet. Es sind aber genau solche Spitzen, die wir zur „Hygiene“ unseres Webportals regelmäßig überprüfen, um Angriffe rechtzeitig zu erkennen.
2.2 Suchanfragen nach Uhrzeit
Extrahiert man aus dem Zeitstempel jeweils die volle Stunde der Abfrage, gruppiert nach diesem Wert und zählt die Häufigkeiten erhält man ein Bild über das durchschnittliche „Tagesverhalten“ eines typischen Familienforschers für die Region Ost- und Westpreußen:

Da die meisten unserer Nutzer aus Deutschland und Polen stammen, und es vergleichsweise wenige Nutzer aus Nordamerika gibt, spiegelt die Grafik das durchschnittliche Verhalten von Nutzern aus einer mitteleuropäischen Zeitzone wider:
Bahnbrechende Erkenntnis: Genealogen schlafen nachts doch!
Während das Suchaufkommen im Laufe des Vormittags kontinuierlich ansteigt erreicht es in den Nachmittagsstunden ein Maximum und bleibt dann bis in die späten Abendstunden auf einem recht hohen Niveau. Erst gegen Mitternacht begibt sich der Familienforscher dann irgendwann zur Ruhe.
2.3 Suchanfragen nach Wochentagen
Ebenso spannend ist die Frage danach, an welchen Wochentagen denn ein typischer Familienforscher seinem Hobby nachgeht. Hier extrahieren wir aus dem Zeitstempel den jeweiligen Wochentag, gruppieren entsprechend und zählen die Anfragen:

Dieses Ergebnis fällt allerdings etwas anders aus, als ich es erwartet hätte. Ich hätte eine klare Präferenz für die Arbeitszeiten an den freien Tagen von Freitag bis Sonntag vermutet. Das Ergebnis zeigt jedoch, dass es einen deutlich erkennbaren Sprung in der Nutzung von Samstag auf Sonntag gibt, und dann die Forschungsaktivitäten im Laufe der Woche kontinuierlich abnehmen. Das Minimum der Forschungsaktivitäten liegt ganz klar erkennbar am Samstag. Ein unerwartetes Ergebnis!
2.4 Mittlere Anzahl von Suchanfragen nach Monaten
Der Eindruck, dass die dunkle Jahreszeit der Ahnenforschung gewidmet ist und der Genealoge sich eher in den warmen Sommermonaten in die freie Natur begibt lässt sich recht einfach überprüfen, indem man aus dem Zeitstempel den Monat extrahiert, danach gruppiert und die mittlere Häufigkeit zählt. Diese leicht modifizierte Vorgehensweise ist notwendig, da nicht alle Monate gleich häufig in dem untersuchten Zeitraum vorkommen:
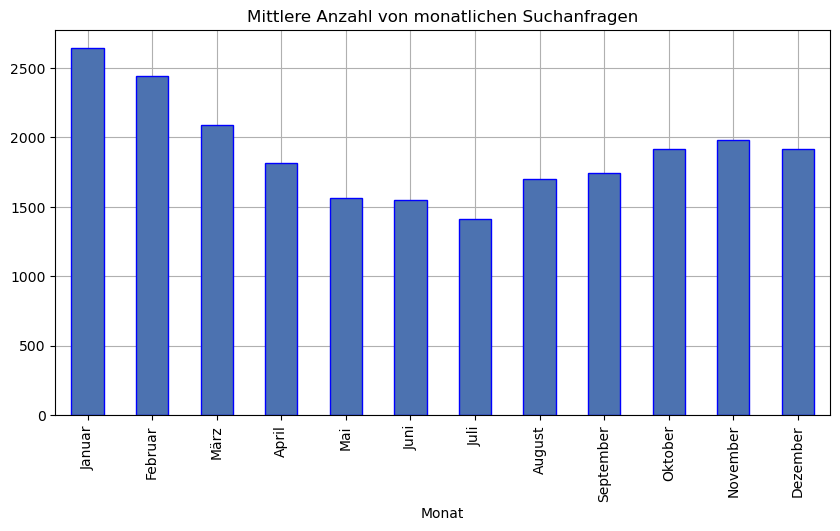
Auch dieses Ergebnis fällt leicht anders aus als erwartet; Die Monate mit den stärksten Aktivitäten liegen ganz deutlich erkennbar am Jahresanfang von Januar bis etwa April. Im Frühsommer bis in den Oktober hinein ist der Familienforscher deutlich weniger aktiv. Erstaunlich ist jedoch, dass die „dunklen“ Monate November und Dezember weniger für die Familienforschung genutzt werden. Scheinbar bedarf es einer gewissen „Anlaufphase“, um die Forschungsaktivitäten wieder aufzunehmen, oder man ist vor Weihnachten stark in die Vorbereitungen der Familienfeiern eingebunden.
3. Kombinierte Auswertung: Die Suchlandkarte
Kombiniert man die Spalten für die Suchbegriffe und die Zeitstempel so, dass alle Begriffe, die in einem bestimmten Zeitfenster von etwa einer halben Stunde gesucht wurden, miteinander verknüpft werden, kann man eine Beziehung zwischen den Suchbegriffen herstellen.
Für diese Analyse vergleichen wir für alle Datensätze die Zeitstempel der Suchbegriffe und berechnen die zeitliche Differenz zwischen ihnen. Je näher die Begriffe zeitlich beieinander liegen, desto wahrscheinlicher ist es, dass sie miteinander in Verbindung stehen. Zumindest haben Familienforscher in einem überschaubaren Zeitfenster nahezu gleichzeitig nach diesen Begriffen gesucht. Alle Begriffe die, nach dieser Definition keine Beziehung zu anderen Suchbegriffen haben können herausgefiltert werden. Je häufiger und je zeitnäher bestimmte Begriffe zusammen gesucht wurden, desto höher ist ihre Beziehung zueinander.
Mit diesen Daten kann nun eine physikalische Simulation durchgeführt werden: Man stelle sich vor, alle Suchbegriffe würden sich grundsätzlich gegenseitig abstoßen und nur durch elastische Federn zusammengehalten werden. Begriffe die eine starke Verbindung zueinander haben, werden durch „starke Federn“ zueinander hingezogen, Begriffe die einen einen schwachen Bezug zueinander haben, entfernen sich weiter voneinander.
Mit Hilfe der freien Open Source Software Gephi kann ein solches physikalisches Experiment durchgeführt und visualisiert werden und es entsteht eine Art Landschaft der verbundenen Suchbegriffe. Als Algorithmus für die Anziehungskräfte verwende ich in Gephi das Modell "ForceAtlas2". Die Suchbgeriffe sind als Kreise in ihrer Größe proportional zu ihrer absoluten Suchhäufigkeit dargestellt und farbig eingefärbt. Nach einigen Minuten Rechenzeit ergibt sich ein spannendes Bild der Suchlandschaft:
Übersicht über die "Galaxie" der Suchbegriffe. Das wirkt auf den ersten Blick noch etwas chaotisch, ist aber trotzdem in gewisser Weise mit einer Ordnung versehen:

Zoomt man in die den rechten, zentralen Bereich der Karte hinein, werden erste Ordnungen der Begriffe sichtbar. Auch geografisch nahe beieinander liegende Ortsnamen finden sich in der Suchlandschaft oft in einer gewissen Nähe zueinander. Das bedeutet, dass in einem Suchzusammenhang häufig nach Orten gesucht wurde, die regional und auch geografisch eng miteinander verwandt sind.

Hier noch ein Ausschnitt der Landkarte um den am häufigsten verwendeten Suchbegriff "königsberg":
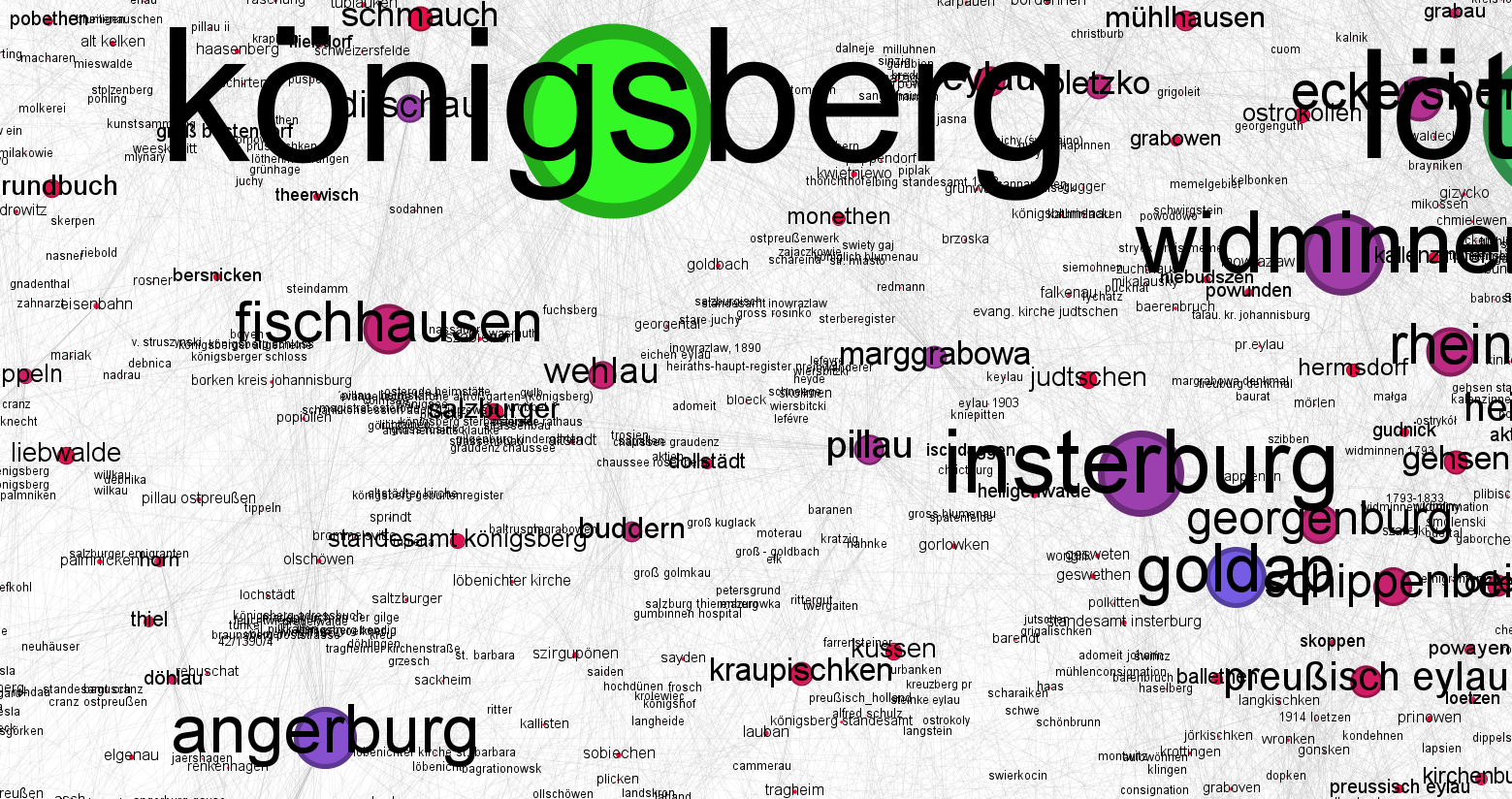
Die einzelnen Bilddateien der Karte können angeklickt werden und das Bild öffnet sich in einem neuen Browser-Tab in etwas größerer Auflösung.
 Facebook über diesen Beitrag diskutieren!
Facebook über diesen Beitrag diskutieren!


©10.12.2023 Clemens Draschba Abrufe Blogartikel: 996007